데이터의 논리적 구조 테이블 및 인덱스 구조 힙 구조 - Clustered Index가 없는 테이블의 경우 비클러스터형 인덱스 구조 트리 구조의 인덱스의 마지막 단계인 리프노드에 해당 인덱스 키의 값과 데이터 페이지의 참조 정보 저장 따라서 비클러스터형 인덱스 키만 가지고 조회를 하는 경우 데이터 페이지를 바라보지 않고 조회를 하게 되어 빠른 검색이 가능함 인덱스의 수정이 발생시 인덱스페이지가 추가되며 각 인덱스 페이지 간 이전, 다음 페이지의 관계가 맺어짐 (해시 테이블 과 같은 원리) 클러스터형 인덱스 구조 - Clustered Index를 가지고 있는 테이블 데이터 행은 Clulstered Index Key에 기반한 순서대로 저장됨 인덱스에 대한 키,값을 가진 리프노드가 없이 바로 해당 인덱스 키로..
데이터 파일 주 데이터 파일[.mdf]과 보조데이터 파일[.ndf]로 구분 기본[디스크가 꽉 찰 때까지 10%씩 자동 증가]로그 파일 가상 로그파일 [.ldf] 최소 단위 256kb로 구성 기본[최대 2TB (2008 기준) 10%씩 자동 증가] page page에 들어가는 항목 8가지 : [msdn 링크] 페이지 유형 내용 데이터 text in row가 ON으로 설정된 경우에 text, ntext, image, nvarchar(max), varchar(max), varbinary(max) 및 xml 데이터를 제외한 모든 데이터가 있는 데이터 행 인덱스 인덱스 항목 텍스트/이미지 큰 개체 데이터 형식: text, ntext, image, nvarchar(max), varchar(max), varbinar..
테이블을 생성할 때 제목에 언급한 4가지 설정이 헷갈리게 되는 경우가많다. Key 와 Index로 나누어 생각하면 된다. index는 물리적인 관점의 데이터 저장에 대한 설정이고 key 는 논리적인 관점의 데이터 저장에 대한 설정이다. (foreign key도 마찬가지) 데이터가 입력될 때 생성되는 index를 위주로 data를 정렬할 것인가 아니면 그냥 data정렬은 하지 않고 index만 추가할 것인가가 바로 Clustered Index와 NonClustered Index의 차이이다. Primary Key는 논리적으로 데이터를 고유하게 식별할 수 있도록 제약조건을 걸어두는 것이다. Primary Key의 제약조건은 다음과 같다. Not Null 중복된 값은 허용하지 않음 하나의 table에는 한개의 ..
컨벤션 문서 모음 코드 컨벤션 : http://java.sun.com/docs/codeconv/ JST 코드 컨벤션 : http://java.sun.com/developer/technicalArticles/javaserverpages/code_convention/ 한글 문서 : http://okjsp.pe.kr/doc/jspCodeConvention.html 프로젝트 컨벤션 : http://java.sun.com/blueprints/code/projectconventions.html 네이밍 컨벤션 : http://java.sun.com/blueprints/code/namingconventions.html JDK 6 한글 문서 : http://xrath.com/javase/ko/6/docs/ko/ JAVA..
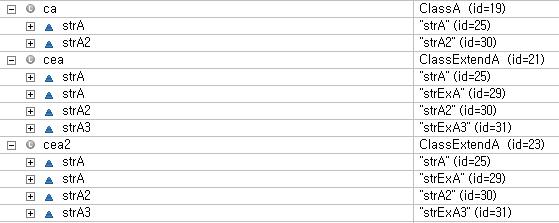
백견이 불여일타. 예제를 통해 이해를 하는 것이 좋은 것 같다. 예제 소스는 다음과 같다. package bluesky.test; public class ClassA { String strA = "strA"; String strA2 = "strA2"; public void methodA() { System.out.println("methodA"); } public void methodA2() { System.out.println("methodA2"); } } 상위 클래스 package bluesky.test; public class ClassExtendA extends ClassA { String strA = "strExA"; String strA3 = "strExA3"; public void metho..
데이터가 있는 컬럼에 대해 인덱스가 만들어질 떄 이 컬럼 값의 히스토그램 및 관련 정보로 구성되는 통계(statistics)가 만들어진다. 검색 조건이 주어질 때 해당 컬럼으로 구성되는 인덱스를 사용할지 여부를 최적화기가 결정하게 되는데 이때 판단의 근거자료로 활용하는 것이 통계이다. 따라서 통계가 업데이트 되지 않은 시점에서 검색조건을 판단하게 되면 최적화된 검색이 이루어지지 않게 된다. 인덱스에 관한 통계는 DBCC SHOW_STATISTICS 명령을 통해 확인할 수 있다. (msdn 참조) 구문은 다음과 같다. DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target ) [ WITH [ NO_INFOMSGS ] [ , n ] ] <..
db에 시간에 대해 저장할 때 datetime과 unixtime 두 가지 방식 중 하나를 이용하여 저장한다. 다음과 같은 query가 datetime 컬럼에 대해 실행되면 어떻게 될까? INSERT 테이블 (날짜컬럼) values(0) 위의 경우 datetime 형식 컬럼에는 '1900-01-01 00:00:00.000'이 저장된다. 만약 int값을 0이 아닌 값으로 실행하면 어떻게 될까? INSERT 테이블 (날짜컬럼) values(1) 위의 경우 datatime 형식 컬럼에는 '1900-01-02 00:00:00.000'이 저장된다. 즉 숫자형의 값을 datetime 컬럼에 입력하면 '1900-01-01 00:00:00.000'을 기준으로 day가 증가 또는 감소한 값이 저장된다. unixtime은 ..
쿼리 튜닝을 아무리 잘 하였다고 하더라도 데이터의 양에 따라 성능이 좌우될 수 있다. 많은 양의 insert, delete 및 update가 이루어지는 테이블의 경우 쉽사리 clustered index를 걸기 힘들다. 이는 인덱스의 재 갱신에 대한 부담이 크기 때문이며, 이런 경우 clustered index는 단순히 identity 컬럼으로 지정하고, 기타 컬럼을 index 지정하여 호출하게 된다. 하지만 이렇게 지정한 index도 문제가 발생할 소지가 있다. 많은 양의 delete와 insert, update가 이루어지면 점차적으로 index가 조각나버리게 된다. 이러한 인덱스 단편화 현상에 대한 체크가 가능하다. dbcc 명령어중 show contig라는 명령어이다. (msdn 참조) 문법은 다음과..