공부 목적으로 설치해 보는 과정을 정리한 것이기 때문에 실제 운영과 다릅니다.
성능 저하 증상 발생
- Windows 10에서 11로 변경하면서 rancher desktop의 설정이 모두 초기화되었고 다시 모두 재설정하였다.
- Swap memory가 모두 사용 중이었다. (확인하는 방법은 아래 참조)
- 작업관리자에서 VmmemWSL의 디스크 사용량이 지속적으로 발생하고 있었다.
계속 디스크를 사용하여서 전체적인 성능이 하락하였다.
디스크를 왜 계속 사용하는지에 대해서는 명확하게 확인되지 않았지만 다음과 같이 진행해 보았다.
- container를 다시 생성하면서 일부 pod가 계속 에러를 발생시켰다.
- 통계 정보 수집하는 pod가 이 에러난 pod의 통계 정보로 계속 디스크 쓰기 작업이 발생시킨 게 아닌가 짐작하고 관련 pod를 모두 다운시켰다.
이 처리로는 해결되지 않았다.
이후 Resouce에 대해 확인하고 설정하기 시작했다.
Resource 확인
Windows Resource 확인
어떤 상태인지 확인을 위해서는 Resource 상태를 확인해야 한다.
Resource 사용량은 Window 작업 관리자에서 간단하게 확인할 수 있다.

또한 좀 더 자세한 내용은 Window 리소스 모니터를 통해 확인할 수 있다.
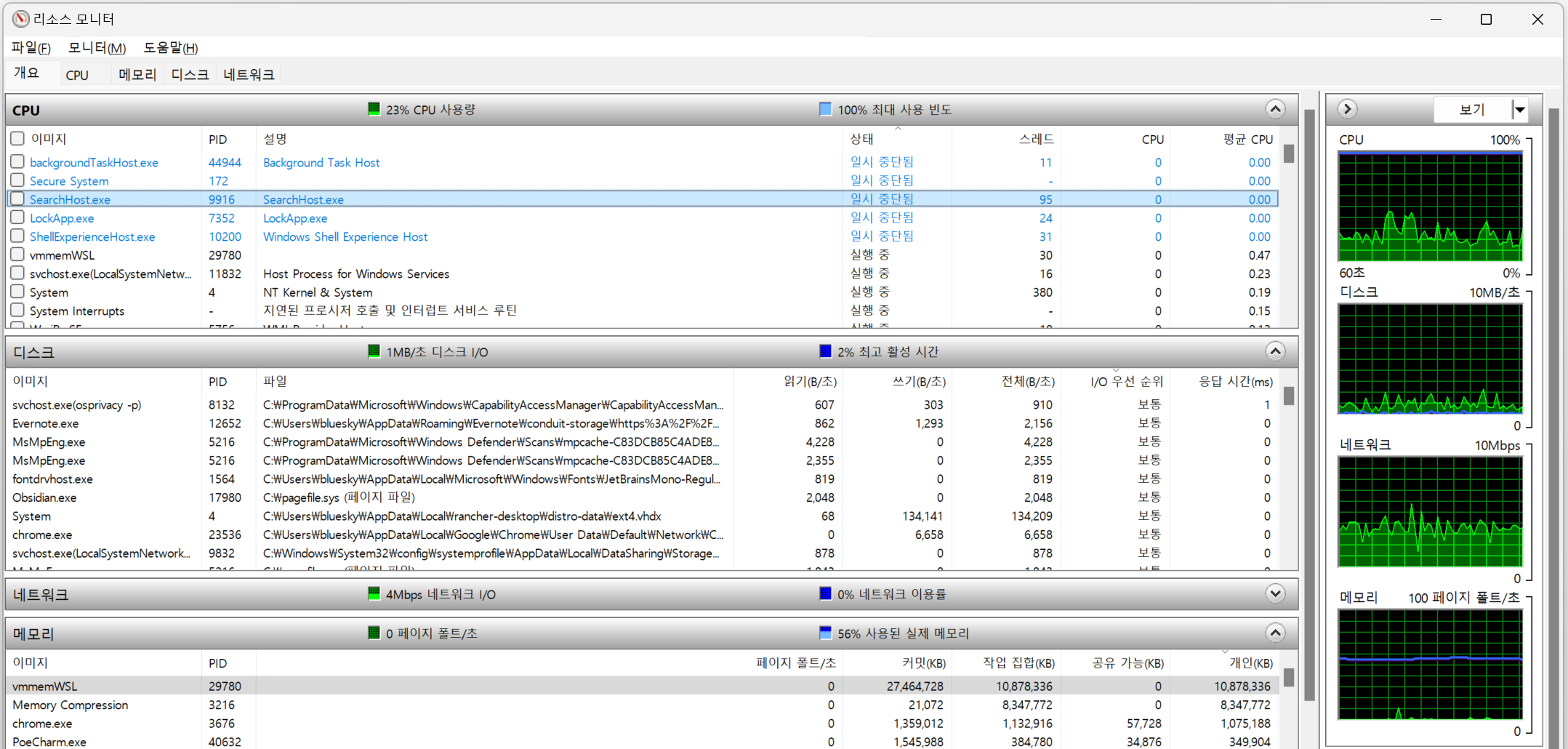
WSL2의 Resource 할당량
WSL2에 기본 할당되는 Resource는 다음과 같다.
https://learn.microsoft.com/en-us/windows/wsl/wsl-config#configuration-setting-for-wslconfig
- CPU : Window에서 사용하는 논리 processor와 동일한 수를 설정
- Memory : 총 Memory의 50% 또는 8GB 중 적은 쪽 (20175 이전 빌드에선 총 Memory의 80%)
WSL2 memory 사용량 확인
16GB 이상 Memory를 사용하는 경우 50%가 WSL2에 할당된다.
64GB를 사용한다면 32GB가 할당되고 32GB를 사용하면 16GB가 할당된다.
wsl의 memory 사용량은 다음과 같이 확인하면 된다.
C:\Users\bluesky>wsl
luversof@DESKTOP-L2MK9DU:/mnt/c/Users/bluesky$ free -h
total used free shared buff/cache available
Mem: 31Gi 18Gi 6.9Gi 236Mi 5.6Gi 12Gi
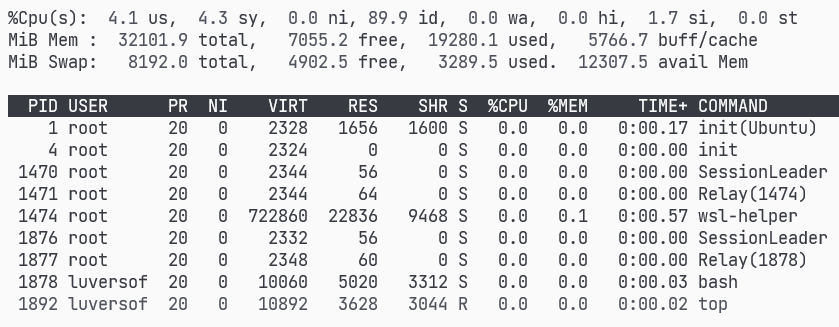
Swap: 8.0Gi 3.2Gi 4.8GiWSL2 CPU 사용량 확인
CPU 사용량은 top 명령어로 확인할 수 있다. (Ubuntu를 사용하는 경우)
Kubernetes Resource 확인
Kubernetes의 사용량 확인
top 명령으로 node와 pod의 CPU와 Memory 사용량을 확인할 수 있다.
C:\Users\bluesky>kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
desktop-l2mk9du 648m 8% 23086Mi 71%C:\Users\bluesky>kubectl top po
NAME CPU(cores) MEMORY(bytes)
bluesky-api-blog-deployment-676c4c6c67-pps6h 3m 254Mi
bluesky-api-board-deployment-85d75d768b-rzlvq 2m 255Mi
bluesky-api-bookkeeping-deployment-7bfcb76847-sctcj 6m 254Mi
bluesky-api-user-deployment-66dc9bc6d7-78lx8 3m 250Mi
bluesky-cloud-admin-server-deployment-8585bdd5bb-phlmb 6m 255Mi
bluesky-cloud-config-server-deployment-6f578b9659-xvqj6 3m 252Mi
bluesky-cloud-gateway-deployment-799fc6f898-2cvmr 3m 252Mi
bluesky-cloud-netflix-eureka-server-1-deployment-f48769b85wbsth 12m 255Mi
bluesky-cloud-netflix-eureka-server-2-deployment-86ccc6955b9g6n 12m 255Mi
bluesky-web-gate-deployment-57f5658db5-b5ppj 4m 251Mi
bluesky-web-swagger-ui-deployment-66b676ffd9-gsrrf 2m 246Mi
elasticsearch-deployment-7697755755-d8jx2 47m 1022Mi
grafana-deployment-588c4d456d-xjcws 1m 158Mi
jenkins-deployment-7f89965f46-2vlz9 1m 442Mi
kibana-deployment-69fc7dcb7c-grcl6 10m 589Mi
loki-deployment-c6d6b8f66-q5frm 6m 104Mi
mariadb-deployment-d7749b87c-fw77h 2m 265Mi
minio-deployment-57f6bc5cb5-bf72n 5m 252Mi
mongo-deployment-6d4d6cfb46-vkptq 5m 170Mi
mssql-deployment-9b74db8db-lb88n 11m 475Mi
nexus-deployment-8486c7cf68-lsd9z 7m 1023Mi
opentelemetry-collector-deployment-6d79f68857-h2qxx 3m 100Mi
prometheus-deployment-548ddc8cd6-t7rv6 2m 136Mi
promtail-daemonset-7d7kc 4m 51Mi
redis-deployment-576959d97d-k4ldz 1m 14Mi
sonarqube-deployment-56ff869486-p59ht 11m 504Mi
spinnaker-deployment-5f9cdcfc4f-9f8kc 2m 853Mi
tempo-deployment-9f48d87cd-gk974 4m 160Mipod의 경우 기본 사용하는 default namespace에 대해서 보여주지만 전체를 보고 싶은 경우 -A 옵션을 사용하면 된다.
kubectl top po -A
# 결과는 생략Kubernetes의 할당량 확인
할당량은 describe node 명령으로 확인할 수 있다.
C:\Users\bluesky>kubectl describe node
... 중간생략
Non-terminated Pods: (44 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default redis-deployment-576959d97d-k4ldz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 26d
default prometheus-deployment-548ddc8cd6-t7rv6 0 (0%) 0 (0%) 0 (0%) 0 (0%) 19d
default loki-deployment-c6d6b8f66-q5frm 0 (0%) 0 (0%) 0 (0%) 0 (0%) 19d
default mariadb-deployment-d7749b87c-fw77h 0 (0%) 0 (0%) 0 (0%) 0 (0%) 26d
default kibana-deployment-69fc7dcb7c-grcl6 0 (0%) 0 (0%) 0 (0%) 0 (0%) 12d
kube-system metrics-server-5f9f776df5-wnr4t 100m (1%) 0 (0%) 70Mi (0%) 0 (0%) 60d
kube-system coredns-597584b69b-rm759 100m (1%) 0 (0%) 70Mi (0%) 170Mi (0%) 60d
... 중간생략
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 8 (100%) 15750m (196%)
memory 4748Mi (14%) 8618Mi (26%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>Resource를 설정하고 나면 node에 할당된 리소스를 확인해서 가용 자원을 체크해야 한다.
Kubernetes Resouce 설정
위에 소개한 여러 리소스 확인 과정을 거치면서 Memory 사용량이 너무 많아 Swap 영역까지 전부 사용하고 있어 kubernetes의 resouce 설정을 하게 되었다.
Resource 관리에 대해서는 kubernetes 문서에 자세하게 나와있다.
https://kubernetes.io/ko/docs/tasks/administer-cluster/manage-resources/
전체적인 리소스 관리의 처리는 다음과 같이 있다.
- container 별 resources 설정으로 pod에 사용되는 container들에 대해 cpu와 memory에 대해 request/limit 제한을 설정할 수 있다.
- LimitRange 설정으로 각 namespace에 대해 cpu와 memory에 대해 기본 max/min 제한을 설정할 수 있다.
- ResourceQuota 설정으로 각 namespace에 대해 전체 cpu와 memory의 request/limit의 제한 총합을 설정할 수 있다.
WSL2에서 kubernetes를 사용하면 이미 WSL2가 기본 memory 제한을 설정하고 있으므로 ResourceQuota 설정을 따로 할 필요는 없어 보인다.
LimitRange 설정의 경우 container 별 resources 설정에 우선하는데 특정 pod의 경우 높은 resouce 사용량을 요구하는 경우가 있다.
이런 경우를 고려하고 LimitRange를 설정하게 되면 (namespace로 아주 자세하게 관리하지 않는 한) 결국 제약이 그리 크지 않아 효율이 떨어진다.
따라서 conatiner 별 resources 설정으로 각각의 container를 관리해 보았다.
resource 설정은 대략 다음과 같이 한다.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"container별로 request와 limit resource를 설정할 수 있고 이 두 가지 설정에 대한 설명은 아래에 있다.
https://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/
pod가 실행 중인 node에 사용 가능한 resource가 충분하면 container가 해당 resource에 지정한 request보다 더 많은 resource를 사용할 수 있도록 허용된다.
그러나 container는 limit 보다 더 많은 resource를 사용할 수는 없다.
- resource 자원을 명시하지 않으면 node 자원 전체를 사용한다.
- 지정된 request 양을 초과하여 사용할 수 있고 limit 양은 초과할 수 없다
- limit를 초과한 cpu의 경우 CPU throttling이 발생하여 성능이 저하된다. (compressible resource임)
- limit를 초과한 memory의 경우 시스템 커널은 메모리 부족 (out of memory, OOM) 오류와 함께 할당을 시도한 프로세스를 종료한다.
- cpu, memory request는 node 별로 100%가 최대치이고 limit는 그 이상을 할당할 수 있다. (pod 생성 시 기존에 할당된 request 수치와 총합 100 이상으로 할당을 시도하면 pending 상태가 됨)
필요 이상으로 많은 memory를 사용하는 pod 들에 대해 resource 설정을 하고 나니 지속적으로 증가하던 memory 사용량이 제한이 되어 성능 저하가 발생하던 문제가 해결되었다.
자원 할당 수치 산정에 정답은 없다.
지속적으로 모니터링하면서 자원 변화에 대해 관리를 해야 한다.
참고 자료
'Study > Docker & Kubernetes' 카테고리의 다른 글
| 로컬 개발 환경(rancherdekstop k8s traefik ingress)에서 https 사용해 보기 (0) | 2025.03.29 |
|---|---|
| Rancher Desktop의 Traefik 사용 시 Dashboard 활성화하기 (2) | 2025.01.05 |
| OpenTelemetry Collector extension 사용해 보기 (0) | 2024.12.27 |
| spinnaker resource (component sizing) 설정해 보기 (0) | 2023.04.07 |
| kubernetes에 Promtail, Loki 사용해 보기 (1) | 2023.03.21 |
| kubernetes에 OpenTelemetry Collector, Grafana Tempo를 설치하고 tracing 구현해 보기 (2) | 2023.03.18 |
| helm chart로 kubernetes yaml 파일 만들기 (0) | 2023.03.17 |
| kubernetes에 sonarqube 설치 & jenkins에서 사용해 보기 (0) | 2023.03.16 |
| kubernetes에 Prometheus, Grafana 설치하고 metric 정보 수집해 보기 (1) | 2023.03.15 |
| kubernetes ConfigMap, Secret 사용해 보기 (0) | 2023.03.11 |


